from __future__ import absolute_import, division, print_function, unicode_literals import warnings warnings.filterwarnings("ignore") import pathlib import matplotlib.pyplot as plt import pandas as pd import seaborn as sns import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers print("Tensorflow Version : " + tf.__version__) import sys print("Python Version : " + sys.version) from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) from sklearn import preprocessing import numpy as np from numpy.random import seed import winsound import os
AI Model Save
These variables allow for the AI model to be saved.
model = build_model() model.summary() # Display training progress by printing a single dot for each completed epoch classPrintDot(keras.callbacks.Callback): defon_epoch_end(self, epoch, logs): if epoch % 100 == 0: print('') print('.', end='')
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=100)
# Create a callback that saves the model's weights cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_weights_only=True, verbose=0)
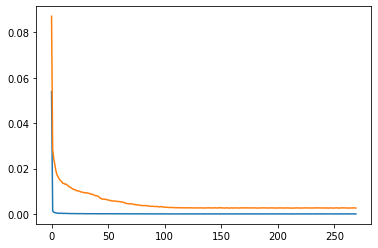
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=0) print("Testing set Mean Abs Error: {:6.4f}".format(mae)) print("Testing set Mean Squared Error: {:6.4f}".format(mse))
1 2
Testing set Mean Abs Error: 0.0011 Testing set Mean Squared Error: 0.0002
The model can predict the closing price of the next bar with a MAE(mean absolute error) of 11 pips. Cross validation will make the result more robust. A LSTM network would yield better results.
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.